Paper-sharing 2018 第九期
2018-04-04
本期分享一篇发表在 Nature Genetics 的一篇文章,文章的题目是The human noncoding genome defined by genetic diversity,理解本文大致需要的知识有:
- noncoding genome的定义
本文创新点是使用了一种新的算法来理解noncoding区域基因组元件的功能,总的感觉这篇文章干货较少,大牛的挂名在文章发表中可能起了重要作用,所以就不展开讲了。
Fig1
首先作者定义了7-mer的核苷酸序列共计4^7=16834个作为这个方法的变量,分别统计了这些7-mer序列在11257个人类基因组个体的全基因组测序数据中出现的频率,同时也根据ENCODE和基因组的注释比较了这些序列在不同区域:如外显子、内含子等位出现频率的差异,如图1.a。之后作者定了一个新的变量 context-dependent tolerance score (CDTS)用来衡量基因组上某一特定区域的对序列改变的耐受性,简单描述就是如果这个值越高,这个区域的序列保守性就越强,就越可能有功能。OK,接下来就进入了作者的自吹模式,图1.b说明保守区域的CDTS都挺高,但是奇怪的是noncoding居然没有专门拿出来说事。
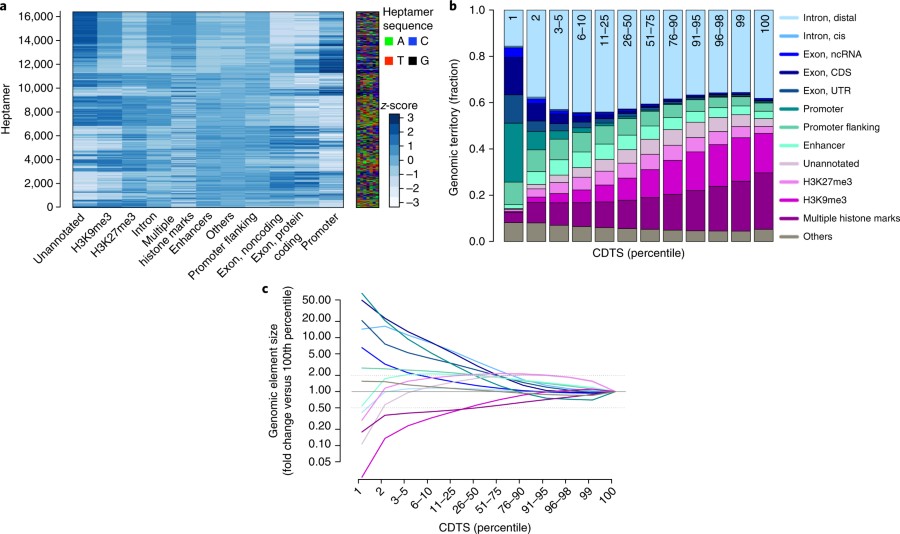
Fig2
图2的问题也不少,首先图二的纵坐标利用了之前研究定义的pLI Score,这个值越大说明基因功能越重要,不能瞎变。可见这个值和CDTS呈现很好的负相关,作者想就此说明自己定义的这个变量还是能衡量一个基因组区域的功能的。图2.b是考虑了enhancer在基因调控中不是直线距离起作用,而可能是长距离的作用机制,于是考虑了Hi-C的数据,但奇怪的是,这个居然没比不考虑空间距离的enhancer趋势要明显(图2.a),并且这幅图中的比较没有设置negative control,所以并不知道是不是算法本身的一些偏差导致了这种相关性。
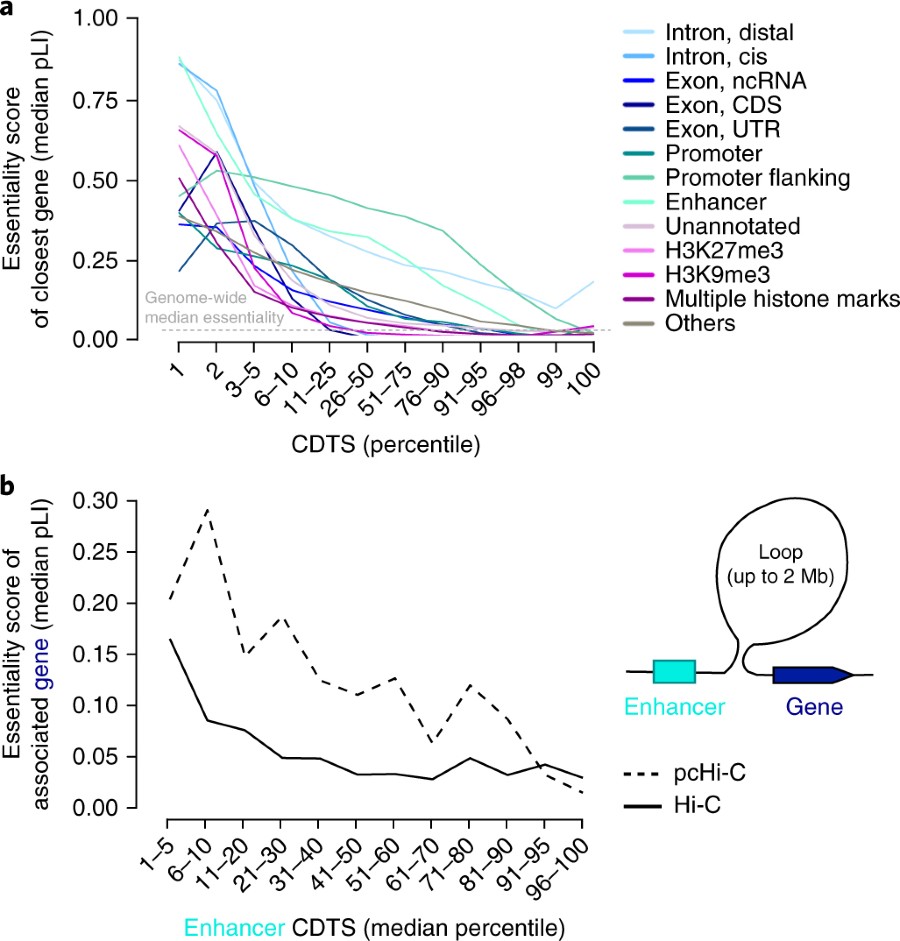
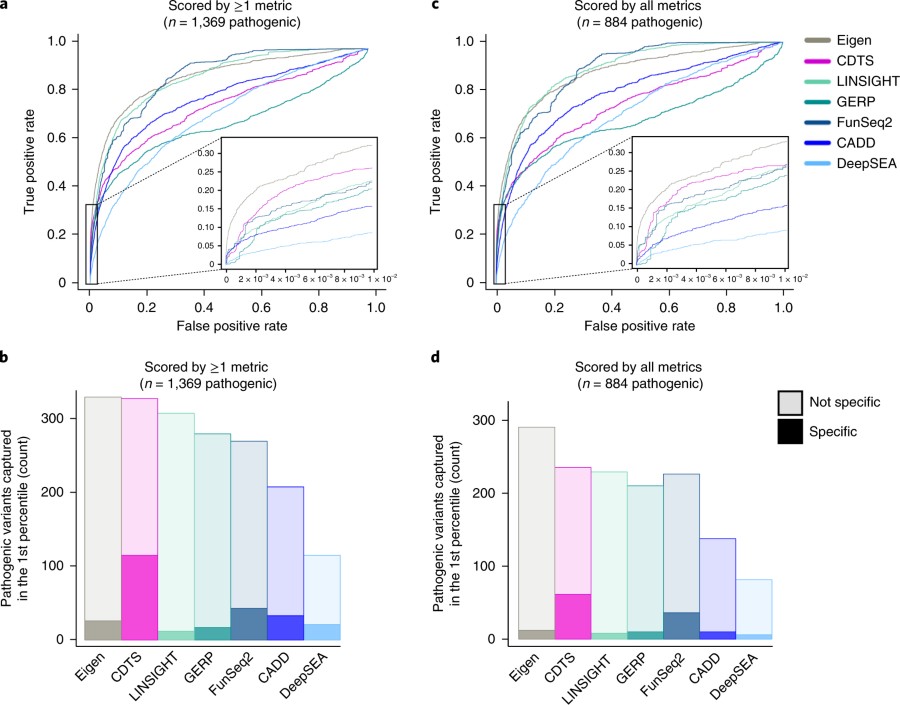
Fig4
图四是作者将本文的算法和之前已经报道的可以识别基因组上重要的元件的算法进行了比较,虽然整体上这个算法不怎么样(看ROC曲线),但作者强行解释说算法在cutoff取得比较小的时候分类还不错,如图中放大部分,这个就很迷,好比说一个人说,我小学成绩不错,老考我们班第一。